Shared Word Diagrams
By: Jeff Clark Date: Sun, 27 May 2007
I have just posted another application for exploring the structure of text documents. This one lets you compare and contrast two documents by showing both the unique and shared vocabulary and the distribution across the documents. Here is an example static image:
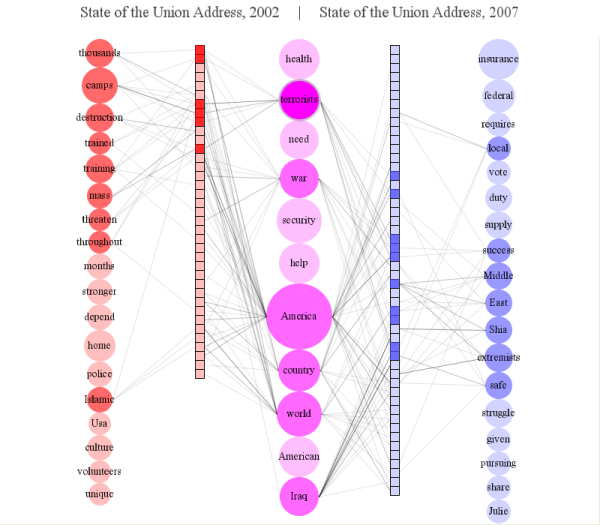
The two columns of squares represent the two documents. The longest document will be shown with 50 segments. In this case, the rightmost blue column is the larger of the two and represents the American State of the Union Address for 2007. The trivial (stop) words were discarded before analysis. For this example the topmost square segment covers the first 51 words of a document, the second segment the next 51 etc.
The leftmost column of word circles show the high frequency words that are present in document 1 (State of the Union 2002) but are not present at all in the second document. The rightmost column of words show those unique to the second document and the central column has the words common to both. The bigger the circle the more frequent the word. The circles are ordered in each column by average position of the word in the documents where they appear which roughly minimizes the number of connection crossings.
Hovering over a word (in the interactive application, not this static image), in this case 'terrorists', will show which segments of the documents contain the word. Darker connecting lines indicate more occurences in that segment. It will also highlight with colour the other words occurring in the same segments. So, for this example, we can easily see that:
- The word 'terrorists' occur in both documents
- It occurs right at the beginning of the speech in 2002 and spans the first third
- It is spread out over the middle third in 2007
- In 2002 it is associated with the words: thousands, camps, destruction, trained, training, mass, threaten, throughout, and Islamic
- In 2007 it is associated with: local, success, Middle, East, Shia, extremists, safe
- In both speechs it is associated with: war, America, country, world, iraq
The interactive application is available here for Shared Word Diagrams. This version lets you enter your own text for analysis - see the form at the bottom of the application. Have fun and let me know if you discover any especially interesting examples.