Neoformix Blog
Random Racer
By: Jeff Clark Date: Mon, 09 May 2022
I've noticed over the last little while that sometimes people use random number pickers to help them make decisions where they want even odds. There are many 'picker wheel' type random selectors available on the web that people use or some are very simple 'pick a number between 1 and N'. I think it is fairly common for teachers to use these as a fair way to choose a student for some task.
It occurred to me that we could make the process much more fun by spreading out the decision over time. I built a little tool that does a simulated race among the choices where each choice has an equal chance of winning. Emoji's are assigned randomly and there are also a few different race strategies to make the results more interesting. Here is an example run:
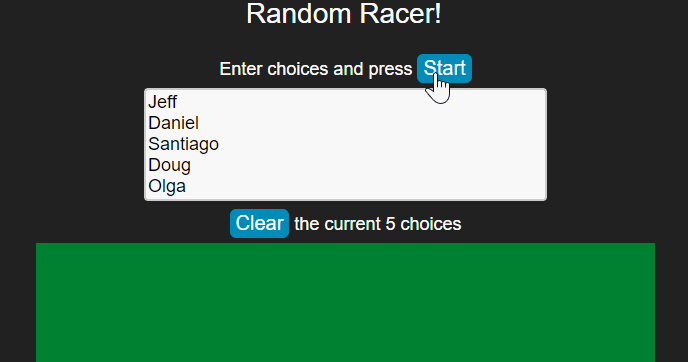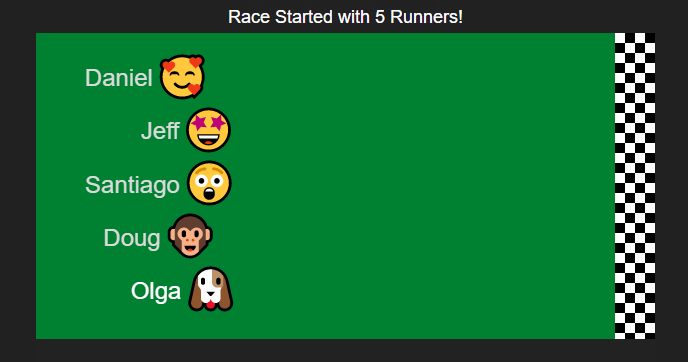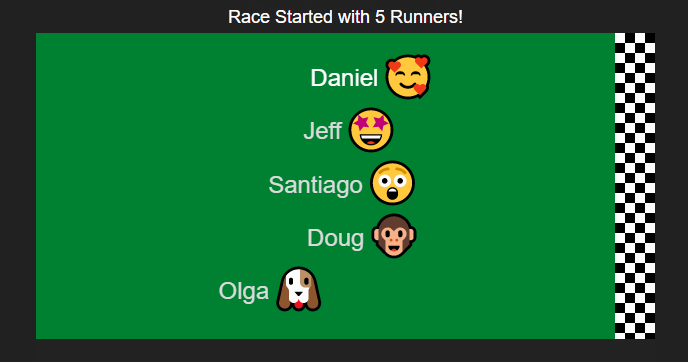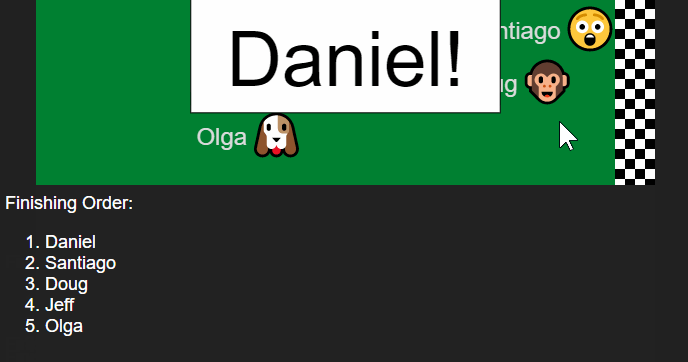
After the race is complete you can scroll down to get the complete finishing order. This is useful if you want to give prizes for 2nd place and 3rd place for example. It can also be used to pick some subset group - choose the top 5 finishers for some task.
The movie below shows an example with 100 random runners. There is obvious overlap but towards the end of the race the names of the leading contenders are legible.
(More...)
FaceFun
By: Jeff Clark Date: Mon, 02 May 2022
Over the last couple of weeks I've been playing with face detection and building fun animations or interesting images on top of an input photo. There are currently three different animated effects that build Gifs and six overlay static effects. Here are some examples of the effects.
Animated Fly: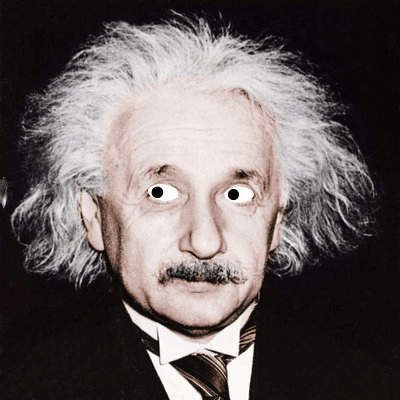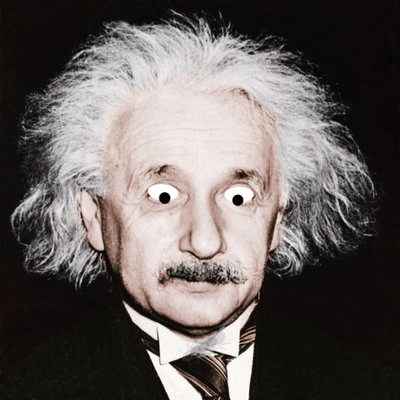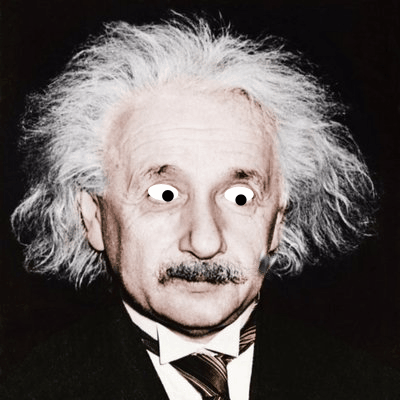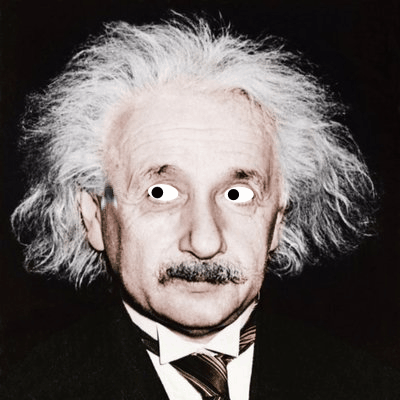
Ear Smoke:

Eye Spin:

Bunny Mask:

Dog Mask:

Cat Mask:

Mouth Eyes:

Eye Flowers:

You can upload any image and try it at Face Fun.
Tileable Animations
By: Jeff Clark Date: Thu, 21 Apr 2022
I have been playing with Gif animations lately and it occurred to me that it is possible to build animation tiles that when placed together build a larger more complex animation. An example of one such tile is shown below.
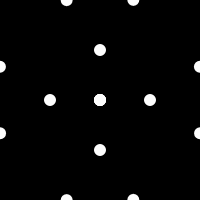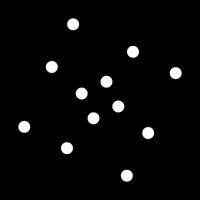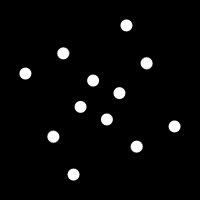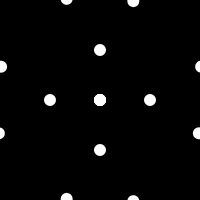
If you place these tiles beside each other they fit together nicely with some dots flowing smoothly from one to a neighboring tile.
Provided you keep the boundary conditions the same you can design an infinite number of animated tiles that fit together perfectly. Here is an example with a random collection of tiles that show more varied motion.

This particular set of tiles have too many that are regular and reveal the center. This makes the compound result look more like a grid. Overall, it's an interesting idea I will likely explore further.
Crazy Phrase
By: Jeff Clark Date: Fri, 25 Mar 2022
It's no secret that Wordle has taken the world by storm in early 2022. It's reportedly been played by millions of people and many of them share their results with friends every day. The game has an elegant simplicity that I find very appealing. I also love the idea of everyone in the world working on the same daily puzzle. It's a lovely example of how a simple digital task can, in some small limited way, build connection and community.
It was evident from the beginning that the simplicity of the game makes it a great starting point for variations. There has been an explosion of games based on the core idea. Here is a list of 67 Games Like Wordle to Play.
I have built one more to throw into the mix. It's called Crazy Phrase and it is available now to play for free. Anyone who has played the original Wordle will find the rules very familiar. Basically, you guess a phrase instead of a single 5 letter word, and there is a new clue color - blue means the letter is present in a different word. Here is a simple example below.

The main difficulty in Wordle is trying to think of words that give you as much information as possible. In Crazy Phrase the words can be very long and for myself, and I suspect many other people, it is very hard to think of long words with specific letters in particular locations. To combat this I chose to relax the requirement that every letter slot needs to be filled. You can leave slots blank and use 2 or more words to fill a one word field. You just need to leave at least one space between words as you would expect. Here is an example of what I mean:
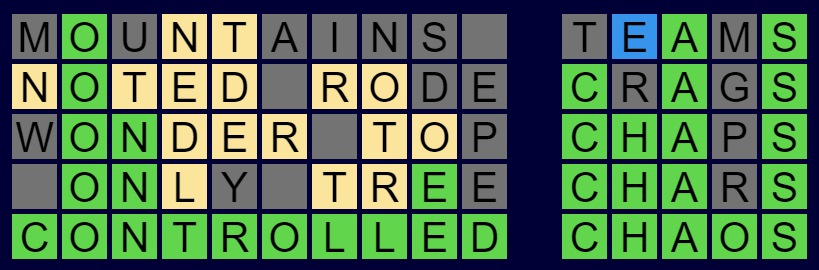
Thank you to Josh Wardle for creating the original game. Thank you also to Jason Davies for creating this implementation of Bloom filters which I used to efficiently do checking of valid words. Thanks also to my family members who have been trying it out for me and Doug Peterson for early use and promotion.
If you enjoy word games then please give Crazy Phrase a try!
GifBuilder
By: Jeff Clark Date: Tue, 22 Feb 2022
I spent some time building a simple online Gif Builder tool. You can enter multiple lines of text (including emojis), customize foreground and background colors, choose one of five animation styles, and press a button to create an animated Gif all in the browser.
Here are a few sample outputs. Give it a try!



Genuary 2022
By: Jeff Clark Date: Tue, 01 Feb 2022
I finished all 31 prompts for Genuary 2022. Thanks to all the organizers and all the wonderful code artists who participated. Thanks also to all the people building powerful tools to make this kind of work more accessible to all. I tried to stick with vanilla javascript as much as possible but did use the amazing three.js, and chroma.js in many of the compositions.
Here is a quick peek at most of the work I produced this month. You can page through each one individually starting here






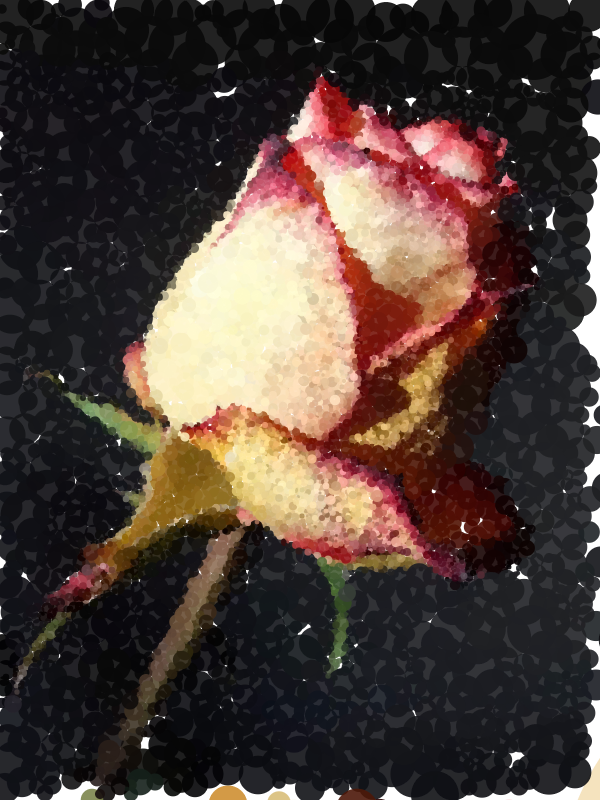


















Genuary 31: Negative Space
By: Jeff Clark Date: Sun, 30 Jan 2022
The prompt for Genuary 31 is 'Negative Space'. I used three.js again and designed a two-faced circle packed arrangement. The animation rotates around 90 degrees to show both faces.
Genuary 30: Organic output with Rectangles
By: Jeff Clark Date: Sun, 30 Jan 2022
The prompt for Genuary 30 is 'Organic looking output using only rectangular shapes'. I made some plant-like shapes from rectangles.
Genuary 29: Isometric
By: Jeff Clark Date: Sat, 29 Jan 2022
The prompt for Genuary 29 is 'Isometric'. I built some scenes in three.js exploring shapes, lighting, and shadow,
Genuary 28: Self Portrait
By: Jeff Clark Date: Fri, 28 Jan 2022
The prompt for Genuary 28 is 'Self Portrait'. I reworked my plant-growing code to grow around an image of my face.
Genuary 27: Fixed Palette
By: Jeff Clark Date: Thu, 27 Jan 2022
The prompt for Genuary 27 is a set of specific colors:
#2E294E #541388 #F1E9DA #FFD400 #D90368
I reused bits and pieces of previous work to create this 3D perspective design.
Genuary 26: Airport Carpets
By: Jeff Clark Date: Thu, 27 Jan 2022
The prompt for Genuary 26 is 'Airport Carpets'. I created a system to make tileable designs from overlapping circles and random color palettes.
Genuary 25: Perspective
By: Jeff Clark Date: Tue, 25 Jan 2022
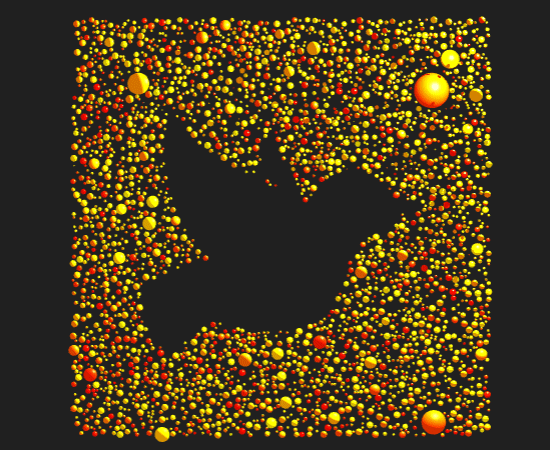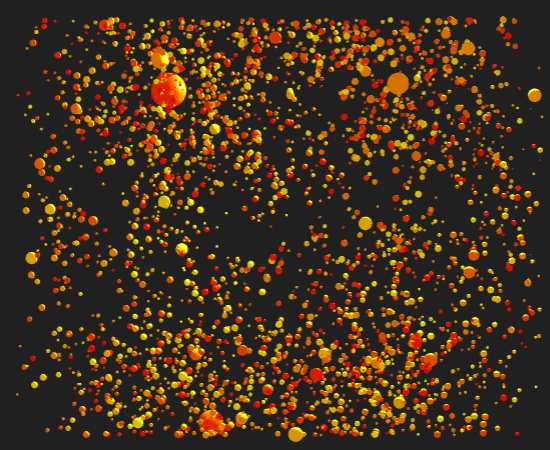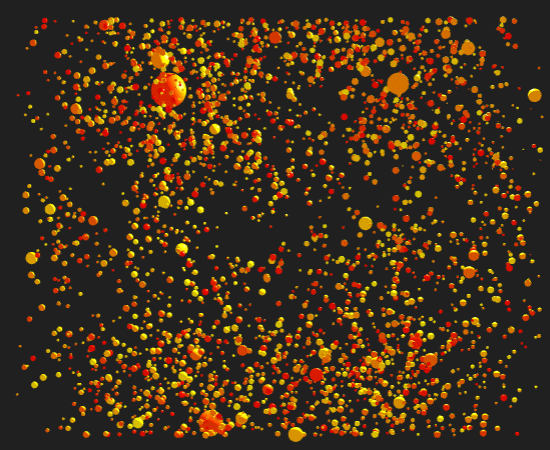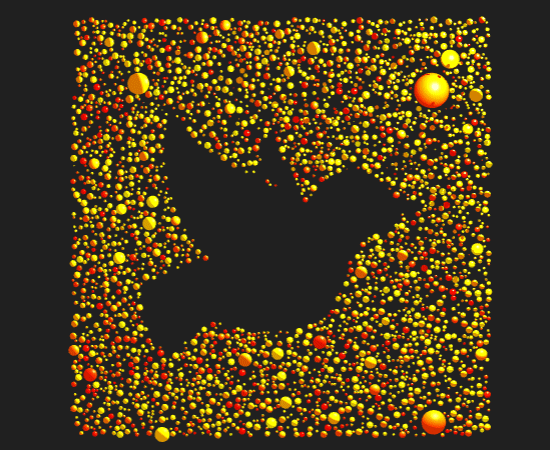
The prompt for Genuary 25 is 'Perspective'. I created a scene with about 2200 colored spheres that when viewed from the proper perspective show an image. This was my first project with the wonderful three.js and I have a lot to learn.
Genuary 24: Create your own pseudo-random number generator
By: Jeff Clark Date: Mon, 24 Jan 2022
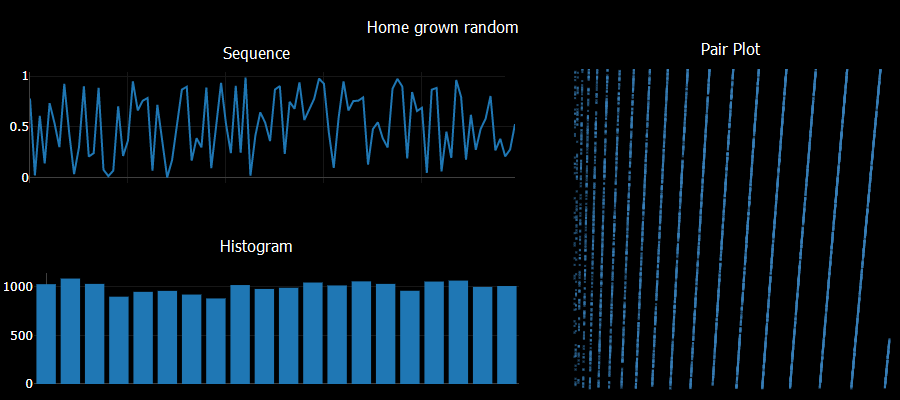
The prompt for Genuary 24 is 'Create your own pseudo-random number generator and visually check the results'. I tried a system like:
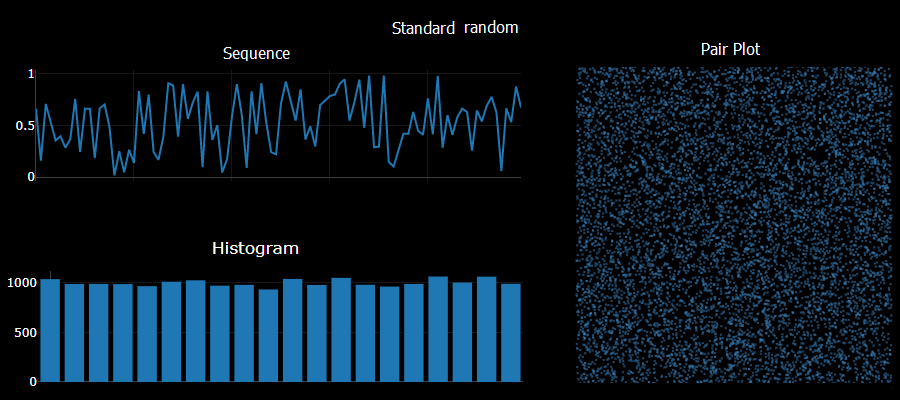
a = Math.sqrt(Math.abs(seed*Math.E))*11 seed = (a - Math.floor(a))Checking sequential generated numbers there are no obvious patterns. Checking the histogram of 10,000 values yields a pretty uniform result. Unfortunately taking pairs of numbers generated sequentially and plotting them shows obvious patterns - a sure sign of a poor quality result. I did try using a larger constant multiple - say 1234 instead of the 11 used above and saw no obvious 2D patterns in that case.
The standard javascript Math.random did very well in comparison on these simple tests.
Genuary 23: Abstract vegetation
By: Jeff Clark Date: Sun, 23 Jan 2022
The prompt for Genuary 23 is 'Abstract vegetation'. I built a simple plant growing system. Plants grow towards the light and avoid obstacles by weaving around them.
Genuary 22: Something that will look different in a year
By: Jeff Clark Date: Sun, 23 Jan 2022
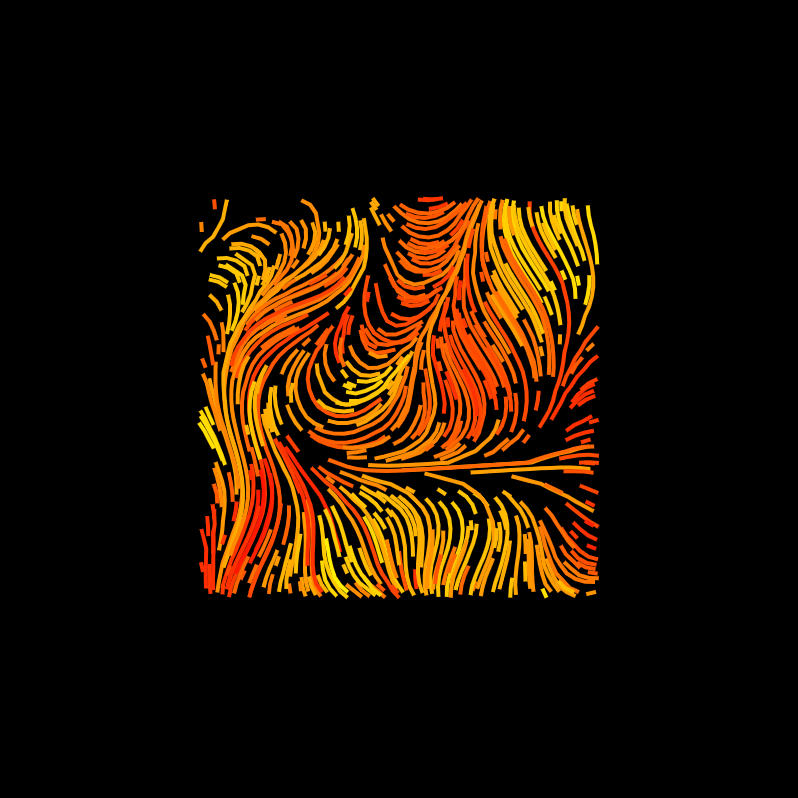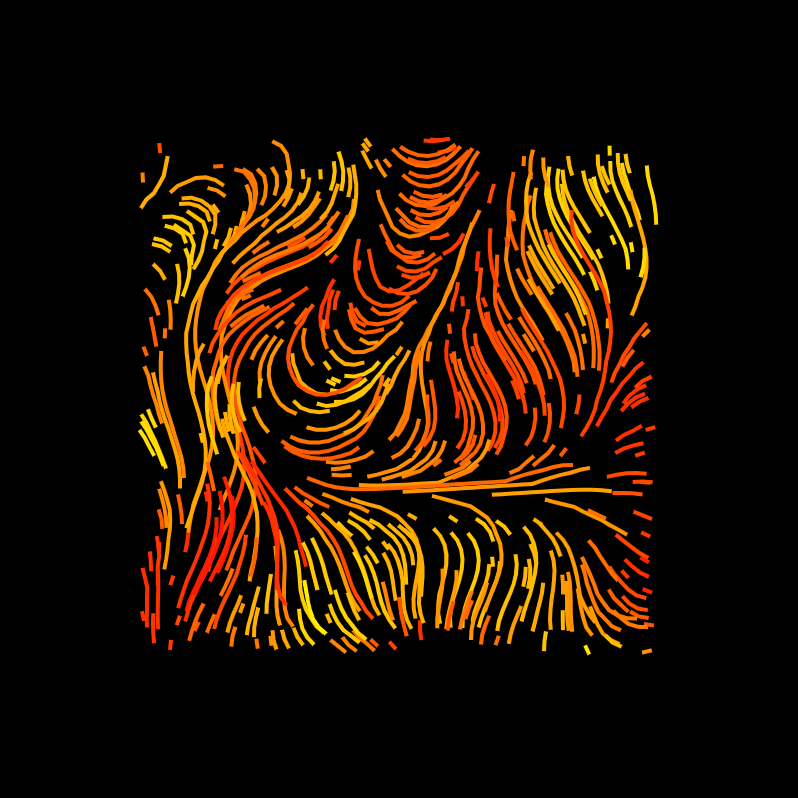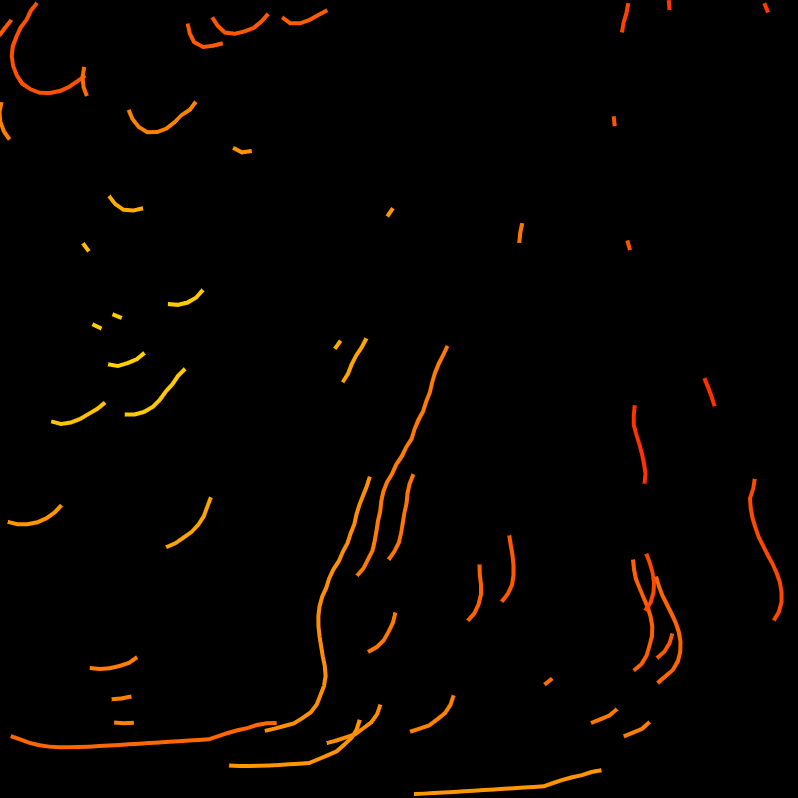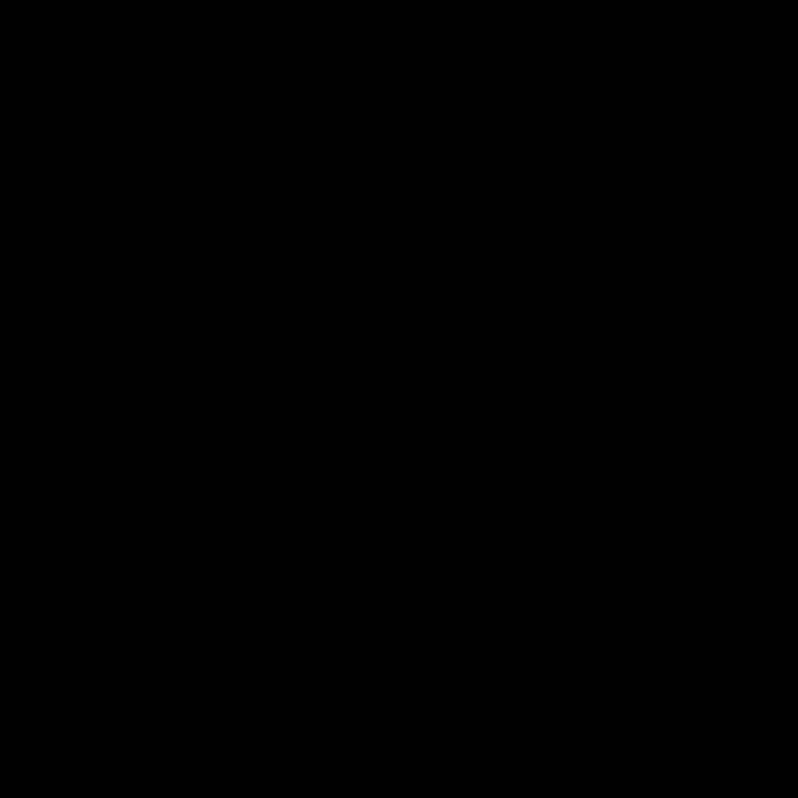
The prompt for Genuary 22 is 'something that will look completely different in a year'. Text reading '2022' along flow lines that are broken by a large version of the text. There are still problems with text collision but I'm moving forward to the next day.
Genuary 21: Combine two or more
By: Jeff Clark Date: Fri, 21 Jan 2022
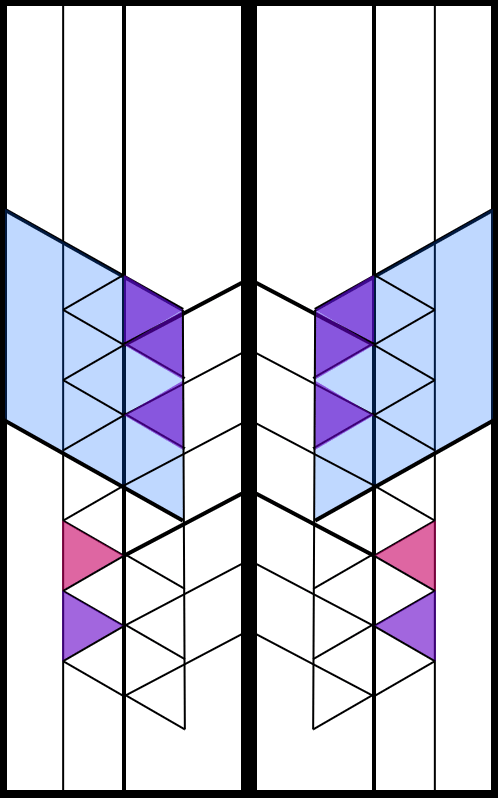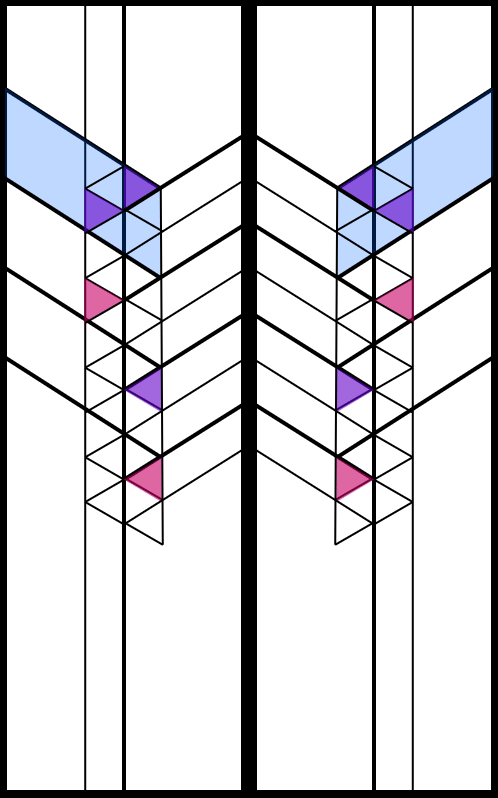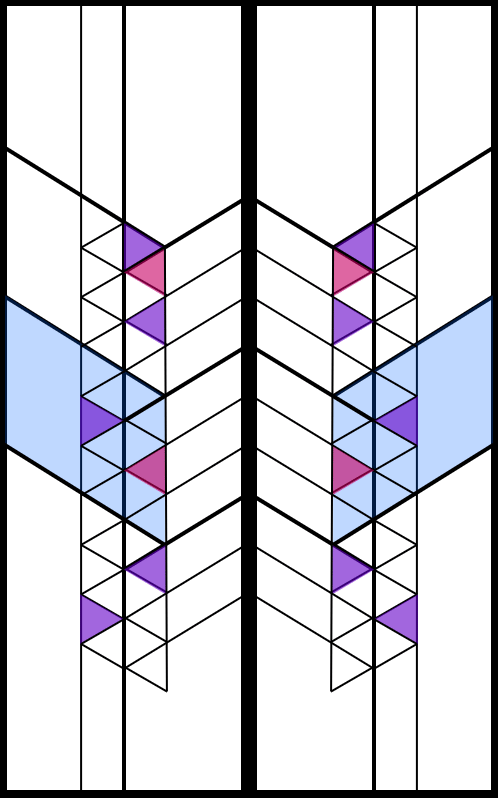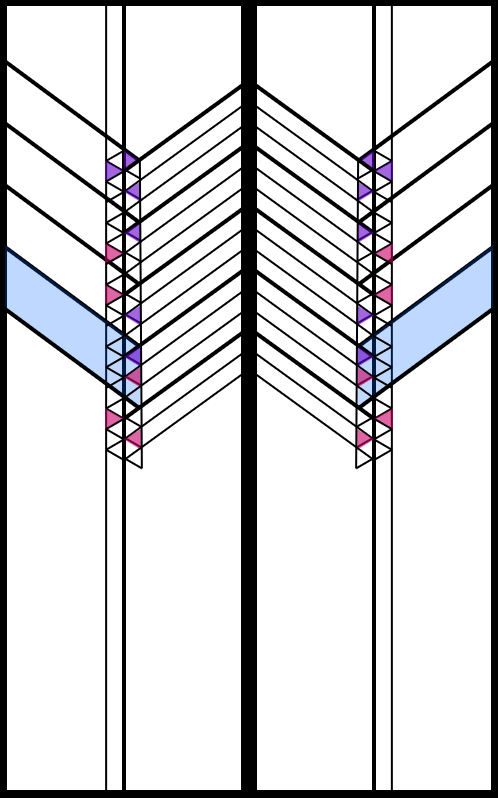
The prompt for Genuary 21 is 'Combine two (or more) of your previous pieces'. This uses the sunset generator but replaces the sun with the Penrose triangle. The final image is dithered to 6 colors using the Atkinson dithering algorithm.
Genuary 20: Sea of shapes
By: Jeff Clark Date: Thu, 20 Jan 2022
The prompt for Genuary 20 is 'Sea of shapes'. I made a generator that uses shapes and textures to make images of a sunset on the sea. I can think of lots of ways to improve it but it shows some promise.
Genuary 19: Text/Typography
By: Jeff Clark Date: Wed, 19 Jan 2022
The prompt for Genuary 19 is 'Text/Typography'. I revisted my single-curve drawing code to draw out the word 'Scribble'. I used a nearest-neighbour approach to connecting points. It's not as good as the simulated annealing approach I used last time but it is much quicker.
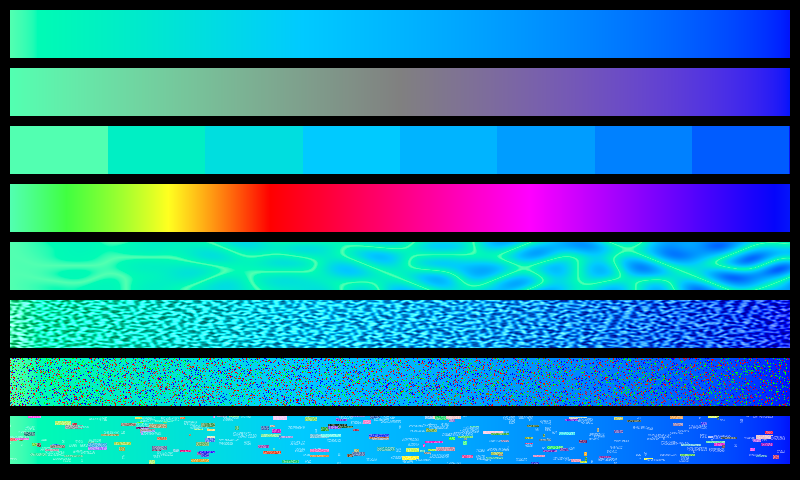
Genuary 18: VHS
By: Jeff Clark Date: Tue, 18 Jan 2022
The prompt for Genuary 18 is 'VHS'. I added a few different types of visual noise reminiscent of the artifacts you see when playing old VHS tapes.