Temporal Correlation for Words in Tweets
By: Jeff Clark Date: Wed, 19 Aug 2009
In my last post, Time Series for Word Counts in Tweets, I showed some graphs illustrating how often a word was used in tweets during the various times of day. I'm using the same data here, 575,962 tweets sent from the Toronto area in the month of July 2009. Some of the graphs show very similar shapes, for example 'morning', 'breakfast', and 'coffee' in the set below.
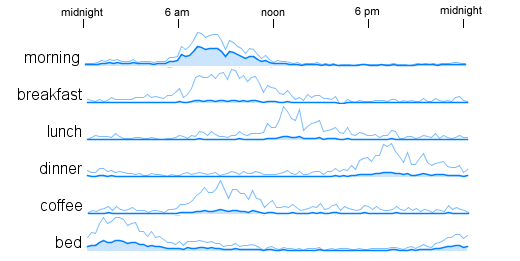
We can spot these visually but if we are analyzing a large number of words, say 1000 or more, it would be useful to be able to calculate the similarity of the curves in order to find matches automatically. We want 'scale invariant' matches - curves with the same shape but not necessarily the same scale. Our curves are just plots of 96 numbers - since I'm summing the counts within 15 minute time buckets and 24 hours * 4 (buckets/hour) = 96 buckets. We can compare two curves by looking at the correlation between their time series values. If the curves go up and down in the same places then they are visually similar and the correlation gives us a way to quantify this.
If we select a time series for a word of interest we can calculate the correlation between that series and each of the others in turn. Then we can show the graphs with the highest correlation to see those with the most similar profile over time of day. Here are the top matches for 'morning':
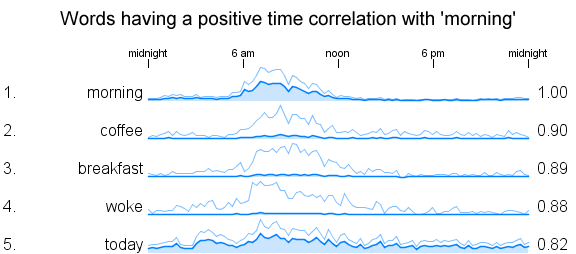
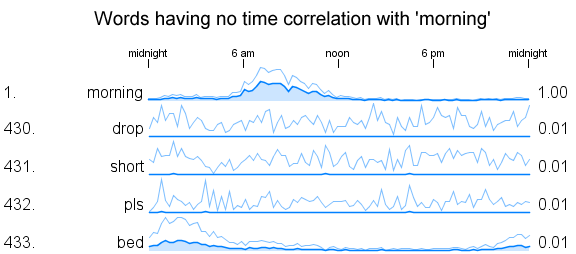
The correlation coefficient is shown to the right of the graph. A value of '1' means perfect correlation, around '0' is no correlation, and a value of '-1' means an inverse or negative relationship. Below are shown some series that show no correlation at all with 'morning'. I was surprised to see that 'bed' isn't used in tweets around the same time of day as 'morning'.
Here are a few examples of negatively correlated words. The relationship isn't quite as strong as for the best positive matches , -.55 compared to +.90 .
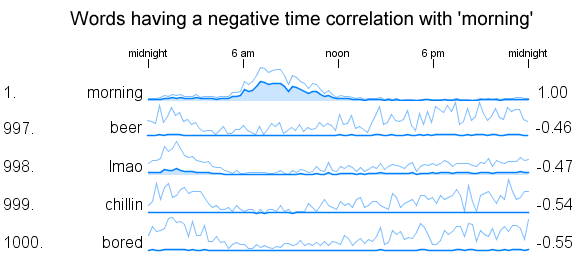
So the word with the strongest inverse relationship with 'morning' is 'bored'. Interesting - I guess people don't get bored in the morning as much as the rest of the day.