Time Series for Word Counts in Tweets
By: Jeff Clark Date: Tue, 18 Aug 2009
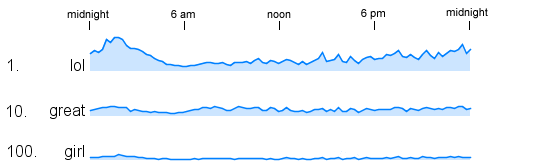
I have been playing around with a fairly large collection of tweets looking into the patterns of word usage over the time of day. The dataset contains 575,962 tweets that were sent out from accounts located within 50 miles of Toronto during the month of July, 2009. For each of the most common 1000 words (except for stop words) I counted how often they were used in each 15 minute period of the day. The counts for all the days in July were simply added together so the shape of the series is for a typical July day. The following graph shows the time series plotted for the most common word - 'lol'.

Both the beginning and end of the horizontal axis represent midnight and noon is in the middle. This graph shows a peak around roughly 2-3am in the morning and a low point around 6am.
If we look at the traces for the #1, #10, and #100 most popular words and keep the vertical scale the same we don't have any detail in the smaller series ( for 'girl' ).
If we scale each graph independently so that the fine details are present for each series then we can no longer tell when looking at a set of graphs which ones have the larger counts.
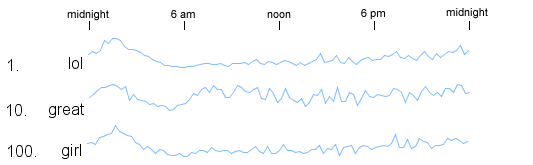
I've been experimenting with drawing both the absolute and independently scaled versions on the same graph so that both the detail and overall magnitude are evident.

It seems to work pretty well. I've used the darker line with the filled area underneath for the absolute scale to give it more prominence.
Here is a set of graphs for some obviously time-dependent terms:
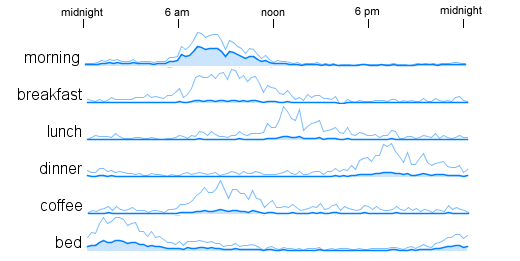
These series seem more interesting than those with a more even distribution over time. Rather than visually scanning a large set of graphs to find these candidates I constructed a metric that measures the clumpiness of each series and used that to focus my search.
There is an obvious similarity evident in the curves for 'morning', 'breakfast', and 'coffee'. In a future post I will describe a technique for detecting these matching curves automatically and show some results based on it.