Twitter Employee Clusters
By: Jeff Clark Date: Thu, 25 Jun 2009
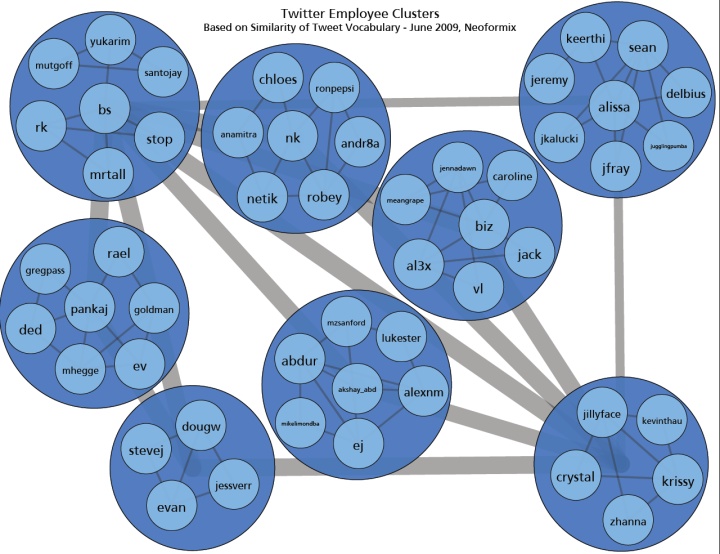
Here is a different view of the relationships between the Twitter employee accounts first presented in this post. I measured the similarity between all the twitter employee accounts based on the overlap in vocabulary used in their last 200 tweets. A clustering algorithm was then used to group them together based on the pairwise similarity scores. The algorithm was tuned to limit clusters to have a maximum of 8 members.
The image below was created from the cluster members data, the similarity between clusters, and the similarity within each cluster. To minimize line clutter I am only drawing a connection if it is one of the top 2 strongest for either end node. The clustering and layout code is based on what I used for the Toronto Twitter Community project but has been recently enhanced to support some new client work.
Here is the PDF version of the Twitter Employee Clusters.